The Integrity Institute’s Analysis of Facebook’s Widely Viewed Content Report (Q4 2021 - Q1 2022)
June 15th, 2022 — Jeff Allen, Integrity Institute
Outline
Anonymous
Unoriginal
Networking
Media Literacy Overall
The top content on Facebook fails media literacy evaluations
Facebook can improve the health of their public content ecosystem
Additional findings
Dashboard
All data and charts are available in our "Widely Viewed Content Report Tracking Dashboard", which we will be updating with each new report. The data can be found in the “Results and Data” section.
Results and Data
You can see all our results in the "Widely Viewed Content Report Tracking Dashboard".
All of the labeled data that went into creating this report can be found in our Google Drive folder
Background and Context
Facebook’s Widely Viewed Content Reports are not without controversy. They also do not provide a comprehensive view into the public content ecosystem that the public needs. But they can be used for some analyses that can illuminate which content the platform most rewards.
Beginning with Q2 of 2021, Facebook has been releasing their “Widely Viewed Content Report”, which presents the content on the platform that reached the most US users. In it, they provide four lists: the 20 most viewed domains, the 20 most viewed Facebook Pages, the 20 most viewed individual links, and the 20 most viewed individual posts.
The list is not without controversy. When the Q2 report was released, it was reported that they had planned on releasing Q1 but held off because they didn’t like what the top content looked like. The purpose of the lists, from Facebook's point of view, is most likely to push back against the narrative that the content the platform most amplified was hyperpartisan and low quality news sources. Facebook felt the need to respond after Kevin Roose began releasing top 10 lists of most engaged content every day on Twitter.
The fact that the entire purpose of the report is strategic in nature, and that Facebook has a history of hiding results it considered embarrassing, means we should have a healthy skepticism of the report. 20 is a fairly small, arbitrary number of results to release, and it’s possible that Facebook could have picked it because the list looks ugly after that. And it would be trivial for Facebook to work to sanitize the top 20 and hide problems they are embarrassed about in the lower positions..
If Facebook wanted to continue to be voluntarily transparent about its public content ecosystem, it could, for example, release a random sample of 10,000 public content impressions every week (or even better, every day, or real-time). This would produce a content-based dataset that was actually representative of the ecosystem and statistically powerful enough to identify most harms. In its current form, the report does not have the statistics to reveal any but the most prevalent harms, and the report could easily be massaged to represent more of what Facebook wants their ecosystem to look like, rather than the true state of the world.
Regardless, the lists do provide a novel view into the Facebook public content ecosystem. And Facebook has consistently said that the most viewed content, rather than the most engaged content, is how they would like their ecosystem to be judged. And so, even though voluntary transparency of this sort does raise concerns, it is worth trying to mine as much insight as we can from the lists.
What Can You Learn From “Top N” Lists?
The best way to develop an understanding of a content ecosystem is to randomly sample content from it, weighted by how many impressions that content got. This is also equivalent to randomly sampling impressions on content. When done properly, the content sample you get from this method is an actual, fair representation of the content ecosystem, and when the sample is large enough, can be comprehensive.
Randomly sampling content impressions is the method that Facebook, Instagram, and YouTube use to estimate the prevalence of harmful content on their platforms, and to be clear, is not the methodology behind the Widely Viewed Content Report lists.
“Top N” lists do not represent an unbiased view. Instead, they represent the content that is most successful and most amplified by the platform. As a result, they are best suited as a quick way to identify problems that are highly prevalent on the platform. If you see a problem manifest itself in the top content on a platform, you should assume the problem is widespread within the overall ecosystem. Platform employees should take problems seen in the top lists very seriously and deeply question how platform design could be making the problems worse.
In addition, if the “Top N” list looks clean, that does not mean that the platform is free from problems.
If you would like more information about what metrics and datasets platforms should release so the public can comprehensively understand the ecosystems they are supporting, please check out our “Metrics & Transparency” and “Ranking and Design Transparency” briefings.
How We Evaluate Social Media Posts
2. We use a set of basic media literacy questions to evaluate the top content. These are questions that are often taught in “Media Literacy 101” style courses.
The most straightforward method to evaluate online content is to ask the basic questions of media literacy:
Who made the content?
How did they make the content?
How are they distributing the content?
Is the content harmful or manipulative?
Why did they make the content?
For each of the top 20 posts and top 20 links that Facebook releases in their reports, we have done our best to answer these questions — except for the last question, which requires more subjective analysis. Here, we present these results over time and a dataset of whether each post or link “Passes” or “Fails” each of the questions.
These questions are really just the basics when it comes to media literacy. For an example of a more comprehensive and deep evaluation, you can look to organizations like NewsGuard.
Who Made the Content: Identity Transparency
Can we find a human name responsible for the content, account, or business? Or is it totally anonymous? To find a name, we include all the information on the Facebook Page itself, including the about us section, as well as any domains that are affiliated with and link to.
For a post to “pass”, there should be real human names of who is producing or responsible for the content on the Facebook Page, or on the affiliated domains, that could be found by a typical user.
How Did They Make the Content: Content Production
Is the account that made the post or link primarily producing their own original content? Or is the account primarily using content from elsewhere on the internet and aggregating content that previously went viral?
For a post to “fail” this check, we must be able to find earlier copies of the content they are posting, which indicates they are not producing any original content.
How Are They Distributing the Content: Content Distribution
Are the accounts sharing their content through networks of coordinated Facebook Pages and Groups? Or are they sharing them primarily through a single account? Inauthentic content producers will typically use a broad network of Pages or Groups, since they care more about how many people they reach than building a meaningful connection with their audience.
For a post to “fail” this check, we must be able to find a set of Pages or Groups that are being used to share nearly identical sets of content, in a spammy fashion.
Is the Content Harmful or Manipulative: Community Standards Violation
Does the content, or the account posting the content, violate community standards of Facebook? Facebook masks content that violates their policies in the lists, as well as accounts that violate their policies in the list. But they do provide indicators when violating content or accounts make it into the top 20 lists.
For a post to “fail” this check, it must be marked as violating in the list, or we must find a hard connection between the link and accounts that have been removed for violations.
Overall Media Literacy Check
We have checked for these basic properties of the content. And we combine the checks into an overall “media literacy check”. For a post or link to pass the media literacy check, it must not be anonymous, must be originally produced, must not be being spread in a spammy fashion, and must not violate Facebook’s community standards.
The Health of the Public Content Ecosystems Matters
3. As long as content that fails basic media literacy can gain broad distribution on the platform, the platform exposes all communities to exploitation.
The Internet Research Agency was an inauthentic organization, run out of Russia, that created a series of Facebook Pages targeting Americans. They were able to reach over 126 million Americans in 2016.
They never told their audience that they were from Russia, obviously, and instead relied on anonymous Facebook Pages.
They didn’t create original content, because they typically didn’t understand American culture well enough to produce original content that Americans would find interesting. Instead, they used memes and articles created elsewhere on the internet that had messages they wanted to amplify.
They used networks of Pages that spammed the same content because they cared more about how many eyeballs they reached than about actually connecting with their audience.
Basic media literacy checks easily flag the IRA’s Facebook pages as problematic. As they do for the Pages currently run out of North Macedonia and Kosovo that target Americans. As the do for Pages run out of Cambodia targeting Myanmar. As they do for Pages that exploit veterans communities for profit.
Being able to successfully target and reach any community on Earth, anonymously, with content stolen from elsewhere on the internet is a key feature of the platform for bad actors. These are the fundamental tools of community exploitation. As long as accounts that fail the most basic of media literacy checks are able to reach large audiences, then the platform continues to be easily exploitable by bad actors who care more about maximizing reach, for profit or politics or trolling, than actually helping users.
Example Evaluations
Identity Transparency
As an example of a link that passes identity transparency, we can use https://www.unicef.org/coronavirus/unicef-responding-covid-19-india.
UNICEF has an executive leadership team which they list, along with comprehensive bios, on their website. Any user should have no trouble finding the people responsible for UNICEF content, as well as their background, motivations, and qualifications.
As an example of a Page and domain that fail identity transparency, we can use “Thinkarete lifestyle”. “Thinkarete lifestyle” was discussed in detail in a Garbage Day newsletter, by Ryan Broderick. It is difficult to find anyone who is actually responsible for it. There are no names on the Facebook Page. It lists “allfood.recipes” as its domain in the About section. But “allfood.recipes” doesn’t have an about us section, and the author of every article is simply “Allfoodrecipes”. Thinkarete links regularly to “lyndaskitchen.com”, but again, there is no actual responsible party listed. The “About Us” page on “lyndaskitchen.com” uses stock imagery and lists the “CEO Founder” as “Robert Downey Jr.” It appears that “lyndaskitchen.com” uses the placeholder text and imagery for the “Martfury” WordPress theme. So not only is “lyndaskitchen.com” anonymous, but it actually misleads its users about who is responsible. “Thinkarete lifestyle” fails our identity transparency check, and we listed it as “Anonymous”.

The leaders are the default for the “Martfury” WordPress theme, “Robert Downey, Jr”.
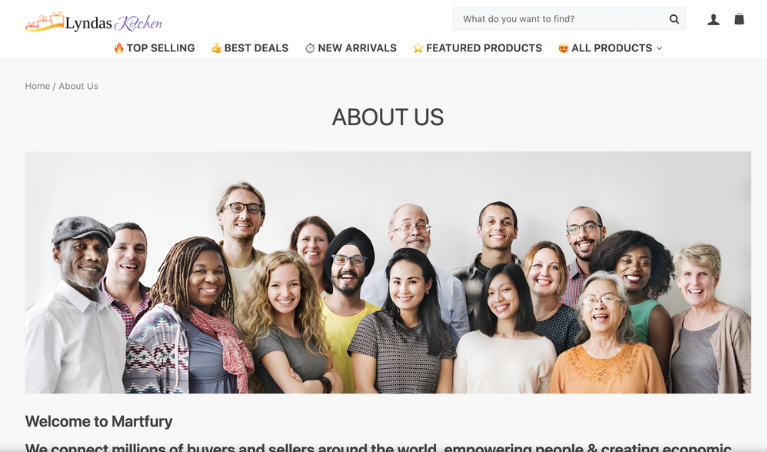
This image from the “About Us” page on “lyndaskitchen.com” may have been taken from WordPress theme defaults.
Content Production
As an example of a post that passes content production, we can look to https://www.facebook.com/watch/?v=214791533793425. This video was probably inspired by these earlier videos: https://www.youtube.com/watch?v=fs44HlrC904 or https://www.youtube.com/watch?v=BouuEDIHJoc.
But the video itself appears to be an original creation of “5-Minute Crafts”, as we were not able to find a copy of that specific video posted earlier.
As an example of a Page that is primarily using unoriginal content in their posts, we can look to “www.playeralumniresources.com”. The content on this domain is original, but the way it is being shared on Facebook heavily relies on memes the owners are aggregating from other sources. The Facebook Page that is most responsible for sharing links to “www.playeralumniresources.com” is “facebook.com/chris.jacke.13”. An example of this Page sharing unoriginal memes can be found at https://www.facebook.com/1484681685114706/posts/3025573837692142 which was shared three days earlier on Twitter at https://twitter.com/mrmikeMTL/status/1431600605504618502.
Content Distribution
An example link that passes our content distribution check and is being shared without the use of spammy Page and Group Networks is “purehempshop.com/collections/all”. The Page that is responsible for almost all shares of that link is “facebook.com/officialjaleelwhitefanpage”. Since this is the only source on Facebook that is regularly sharing that link, it does not appear to be using networks.
An example link that fails our content distribution check is “https://www.youtube.com/channel/UCQ0J6PwaunVnt8gE8DQunOg”. This link was shared across a network of Pages and Groups, which are all clearly coordinated.
https://www.facebook.com/CraftnTips27022019/
https://www.facebook.com/CreativeArt17719/
https://www.facebook.com/groups/714913072224154/
Community Standards Violations
The posts and links that violate community standards are usually fairly clear, since Facebook masks them in the list.
The cases that we labeled as violations that weren’t masked are in the 2021 Q4 report:
https://www.tiktok.com/@thataintrightofficial/video/7032866424154590510
https://www.tiktok.com/@thataintrightofficial/video/7036788676420013358
https://www.tiktok.com/@thataintrightofficial/video/7032148562813275439
We labeled these as violating because, thanks to reporting from Garbage Day, it is fairly clear that these links are associated with a Facebook Page named “That Ain’t Right” which was removed from Facebook for community standards violations. The account was also removed from TikTok. Because the links are quite clearly linked to a Page that Facebook removed, we are also labeling these links as violating.
Analysis for Q4, 2021
Aggregated Results
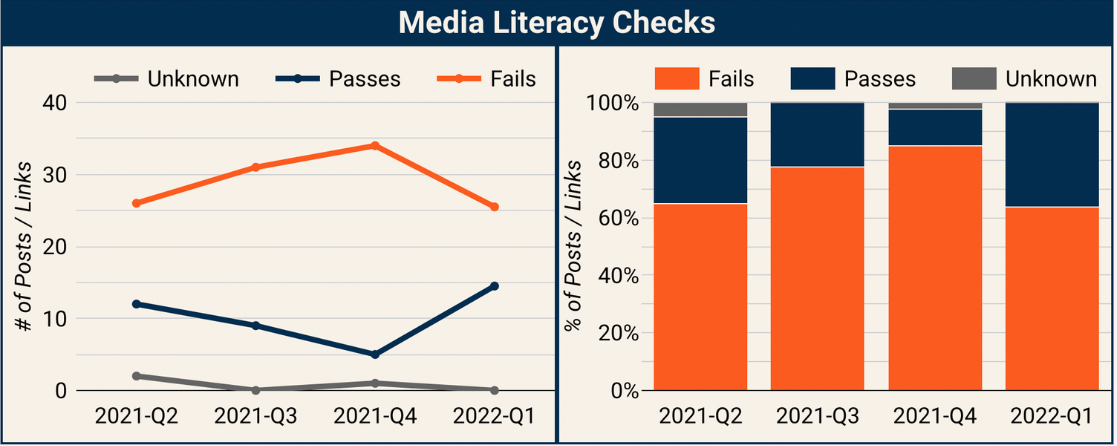
4. Content that fails our media literacy evaluation is highly prevalent in the top content on Facebook. Only about 20% of the top content actually passes all of our checks.
Results: Identity Transparency

Anonymous accounts have gone from covering 5% of the top links and posts in Q2 of 2021 to 45% of the top links and posts in Q4 of 2021. This shift largely reflects a change in the content Facebook itself is specifically amplifying in people’s News Feeds. In Q2 and Q3, Facebook was specifically boosting posts from UNICEF, the CDC, and other authoritative sources of health information, all of which have excellent transparency as to who their leaders are.
In Q4, Facebook appears to have stopped amplifying health links, and replaced them with Instagram Reels. The majority of the Instagram Reels that Facebook added to people’s News Feed come from anonymous accounts, which is reflected in the sharp rise in top content that fails our identity transparency checks. We discuss this amplification of Instagram Reels later in the article.
Results: Content Production
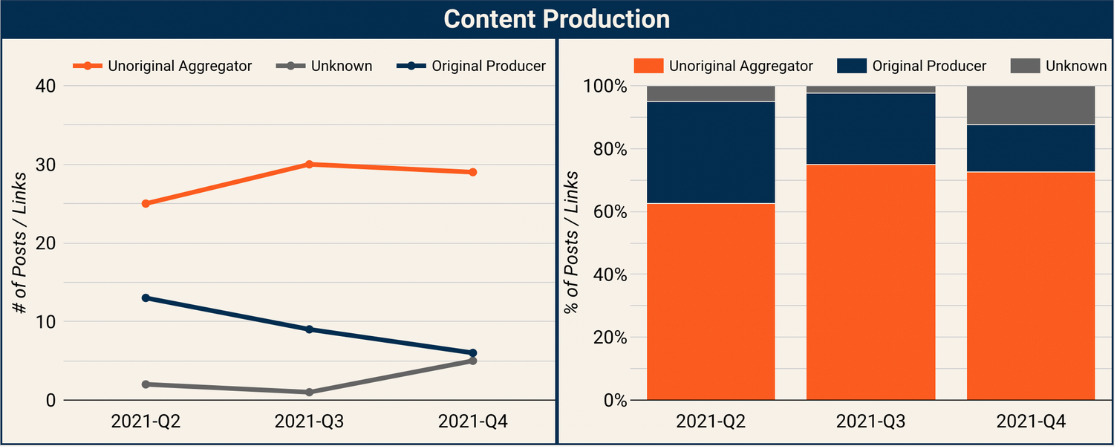
Unoriginal content has always been a majority of the top content on the platform, and that has consistently been the case across all reports. The most common use for unoriginal content is to recycle memes, jokes, or questions that had previously gone viral on other platforms. We found content that was originally produced for Twitter, Reddit, Quora, and YouTube being reposted onto Facebook and gaining very broad distribution.
In Q4, we get our first view into the Instagram Reels ecosystem, and how frequent unoriginal content is there. Overall, unoriginal content in Instagram Reels appears to be about as prevalent as in Facebook overall, and so there isn’t a significant shift from Q3 to Q4.
Results: Content Distribution
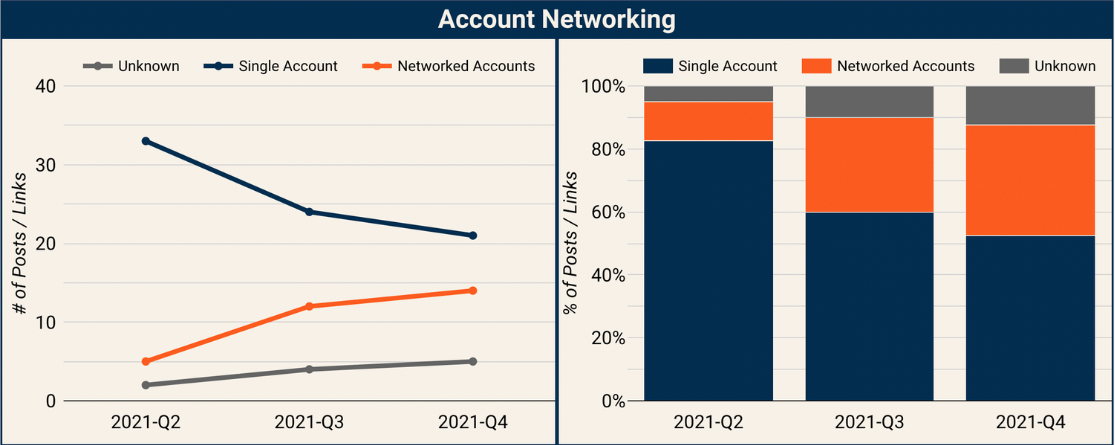
It is not uncommon for top content on Facebook to come from accounts that are engaging in spammy behavior across a network of Pages and Groups. And that has consistently been the case across all the reports. The most common tactic is to use a series of Facebook Pages that post nearly identical streams of content. But there are also examples of accounts coordinating across Facebook Groups to post identical streams of content.
Results: Community Standards Violations

It should be shocking that content that violates community standards appears in the top content lists. Violating content appearing in top lists should set off alarm bells internally, and when the number one most viewed Page on the platform is removed for violations, that should be a genuine 5-alarm fire.
The fact that 10% of top content in the Q4 report can be traced back to a violating account is genuinely shocking and represents a genuine failure to build ranking and distribution systems that are in alignment with the company’s mission and values, as well as resilient against harmful content and exploitative actors.
Results: Media Literacy Check

We can combine all these evaluations together to assess how much of the top content on Facebook fails basic media literacy checks. Any post or link that fails any of the checks, meaning either they are anonymous, or posting unoriginal content, or using spammy Page and Group networks, or posting violating content, will be marked as “Fails”.
We see that top content primarily fails our basic media literacy test. And it has actually climbed throughout 2021 from 65% of the top content failing to 85% of the top content failing. One driver of this is that boosted health posts, from UNICEF, the CDC, and other authoritative health organizations, no longer show up in the top content. And instead, Facebook has been amplifying Instagram Reels, which typically fail our media literacy checks. Overall, there has been a fairly dramatic shift in content quality over the course of 2021, in a negative direction.
The Top Content on Facebook Fails Media Literacy
5. By empowering content producers that fail the most basic media literacy checks with huge audiences, Facebook is exposing communities and users on their platform to large risks from bad actors wishing to exploit them for narrow self interest.

These results speak volumes about the health of the public content ecosystem on Facebook. The top performing content is dominated by spammy, anonymous, and unoriginal content. This clearly indicates that Facebook does not take even the most basic media literacy principles into account in their platform design and ranking systems.
This has profound repercussions. Disinformation operations depend on their ability to reach audiences while maintaining anonymity and being able to deliver relevant messages to the communities they are targeting. The IRA, as well as the North Macedonian and Kosovan, troll farms all operated accounts on Facebook that were anonymous and posted primarily unoriginal content. And to this day, disinformation operations targeting communities in Asia are still able to successfully use the same tactics, recently shown for operations targeting Myanmar.
We should not be surprised that “news” on Facebook is dominated by hyperpartisan opinionated hot-takes from outlets that base all their content on original reporting that other outlets do for them. We should not be surprised that conspiracy theories can appear out of thin air and quickly run rampant across the platform. When the top content of Facebook fails the most basic media literacy evaluation, all of this should be expected.
What this really indicates is that the platform is easily exploited. And while the platform is vulnerable, we should expect exploitative actors to be heavily using it. Platforms will forever be playing “whack-a-mole” with hostile actors as long as they leave their users so exposed.
Other Platforms Are Better at This
6. Other platforms have had success in developing content distribution systems that reduce the spread of content that fails media literacy evaluations.
Facebook and Instagram are fairly unique in the high prevalence of anonymous, unoriginal, and violating content among top performing content. You can see the top content on YouTube from the past week here, for example. And none of it is unoriginal, none of it is from anonymous sources, and none of it appears to be spammy.
The platform that most comprehensively solves this problem is Google Search. Google Search uses their "Search Quality Evaluator Guidelines" to define both high quality and low quality content. They include content from anonymous domains and domains that are copying content from other sources to be in the "lowest" quality bucket. This means that a huge chunk of Google Search's ranking systems will be trained to not give high rankings to this exploitative content. And it has been largely successful. Google Search has never had scandals like the IRA or North Macedonian troll farms gaining prevalence.
Facebook Can Improve the Health of Their Public Content Ecosystem
7. There are methods that Facebook could adopt to improve the health of their public content ecosystem.
An example of how Facebook could tackle this problem, comprehensively, can be taken straight out of Google Search’s playbook. Facebook could define anonymous and unoriginal content as “low quality”, build a system to evaluate content quality, and incorporate those quality scores into their final ranking “value model”.
Facebook could even use core signals that Google Search uses for quality assessment, like PageRank. PageRank is the original, key algorithm that set Google Search apart from all other search engines back in 1999. It works by analyzing the collection of links across the entire web. The more links that point to a certain domain, the more “vetted” it is, and thus will have higher PageRank. If a domain with a high page rank links to another domain, that domain will also have a high PageRank score.
At the Integrity Institute, we have extended this concept into the social internet. Instead of tracking only domains, we also track social media accounts, and include them in the PageRank calculation. This means that individual Facebook Pages, like facebook.com/unicef, can be assigned a PageRank score, and fairly compared to other social media accounts (Like Twitter accounts or YouTube channels) and domains.

We have computed the PageRank for every domain and Facebook Page that has shown up in the top content lists. Our results show that with a single algorithm like PageRank, we can already easily separate content that fails media literacy checks from content that passes. In our current calculation, posts and links that score in the range 0-2 are 87% failing, while posts and links that score 3 or above at 93% passing. We plan on releasing this dataset soon to the public.
If Facebook incorporated more signals like PageRank into their content ranking algorithms, they could easily begin to make substantial progress in cleaning up their public content ecosystem.
Health Links Are No Longer Top Content

At the start of the pandemic, Facebook announced that they would be promoting content from trustworthy sources of health information, including UNICEF, AARP, and other organizations. In both the Q2 and Q3 reports, we saw examples of content from these sources in the top links lists as well as in the list of top domains. In Q4, these sources do not appear in any of the top lists, which may mean Facebook has stopped amplifying, or reduced the amplification, of health links from authoritative sources.
Facebook Is Promoting Instagram Reels
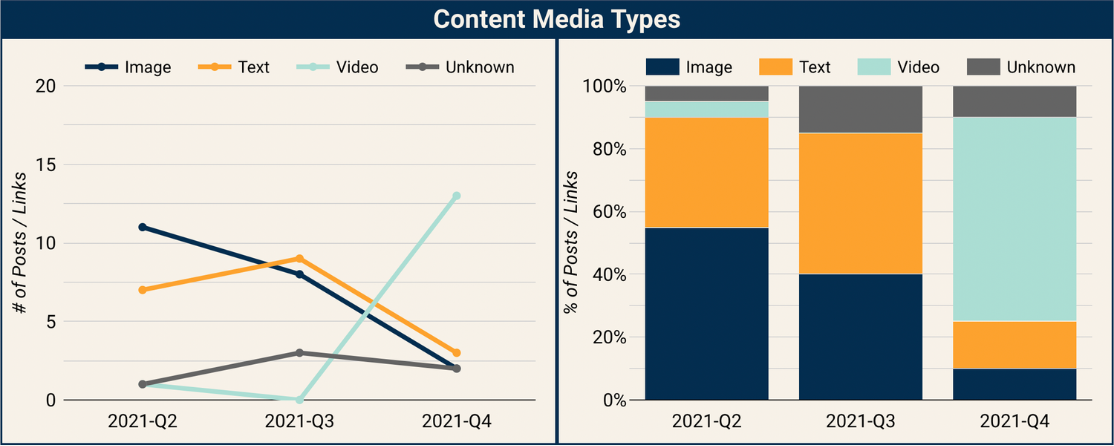
In the Q4 report, 11 of the top posts on Facebook are actually Instagram Reels. Facebook began adding suggested or recommended Reels into peoples News Feeds last year, and we now see that Facebook has been pushing Reels very heavily. Before this change, it was uncommon for a video to make it into Facebooks top posts, but now, video is the dominant media type. These Reels are showing up in a "Suggested For You" unit in News Feed, and it would appear that most of the content is unconnected, meaning from Instagram accounts that people are not following.
This actually gives us a small view into the Instagram Reels ecosystem. What type of content is succeeding in Reels? We see that a very similar story is playing out there. Reels is dominated by anonymous accounts posting unoriginal videos they have aggregated from elsewhere on the internet.

Of the 11 Instagram Reels, only 2 of them pass our basic media literacy test. The rest are from anonymous accounts that post primarily aggregated content for the purpose of building audiences. Many of the accounts include "DM for Promotion" in their Instagram bio, suggesting they are trying to get people to pay them to post ads.
The Top Reels Are Mostly About Fighting and Conflicts
If we take a subjective look at the Reels that Facebook is heavily promoting in peoples News Feed and ask, “What are they about?”, we find a disappointing situation: Most of the Reels are about fighting and conflicts. This can be easily seen by looking at the thumbnails of all the videos.

Of the 11 Reels which showed up in the top 20 Facebook posts, 7 of them were clearly focused on people fighting with each other, sometimes physically, sometimes verbally.
It is important to stress that these are all recommended Reels. The vast majority of Facebook users who were shown these videos never chose to follow the accounts that uploaded them. The reason these appeared on the top 20 list is entirely due to Facebook’s decision to show recommended Reels in News Feed, and the algorithm that decides which Reels to show Facebook users.
It is disappointing that Facebook, which has such a strong mission statement of “empowering people to build community and bring the world closer together”, has somehow decided that the best way to accomplish that mission is to show people videos of fights and confrontations.
Results and Data
You can see all our results in the "Widely Viewed Content Report Tracking Dashboard".
All of the labeled data that went into creating this report can be found in our Google Drive folder
Analysis for Q1, 2022
Summary
Content that fails basic media literacy checks, as well as content that violates Facebook’s community standards, continues to be extremely prevalent in the top content on Facebook
Facebook has changed how they count views on links
This completely changes the list of most viewed links
Going forward, we expect anonymous and unoriginal content to decrease from this change
NB, this is an accounting change and does not reflect any meaningful change in the Facebook user experience
Anonymous and unoriginal content being used to spam links will still be very prevalent on the platform, we just won’t see them in the new lists going forward
The return of “Pivot to Video” continues, and video is again the dominant media type in the top posts
We’ve been forced to add “Misinfo” and “Inauthentic” labels to our violating content and identity transparency evaluations
A link that Facebook fact checking partners have labeled as misinformation is the fourth most viewed link on the platform
A link that is being spread by a coordinated and inauthentic network of accounts and groups is the ninth most viewed link
The prevalence and diversity of violating content among the top content on the platform is genuinely alarming
Facebook needs to expand the lists beyond just the top 20
Facebook needs to expand these lists globally
It is not acceptable for this much violating content to be in the top for the most covered country. And every country deserves to know what the list looks like for them.
What's New?
We are seeing a few shifts in the prevalence of content that fails basic media literacy checks. The overall rate of failures has returned to the same rate we saw back in Q2 2021. We are seeing less anonymous content and less unoriginal content that we saw at the peak in Q4 2021. However, most of this change can be attributed to a change in how Facebook defines a “link”, and so most of it doesn’t reflect any change in the actual user experience on Facebook.

Content that fails basic media literacy checks, including content from anonymous sources, content from sources that are systematically taking content from other creators, content from sources that use networked assets to boost distribution, and content that violates Facebook's community standards, continues to be extremely common among the top viewed content on the platform, and makes up the majority of the examples Facebook shares in the new lists.
Pivot to Video II Continues
The “pivot to video” that we saw take place in Q4 of 2021 continues. Videos, mostly Reels, now make up 15 of the top 20 posts.
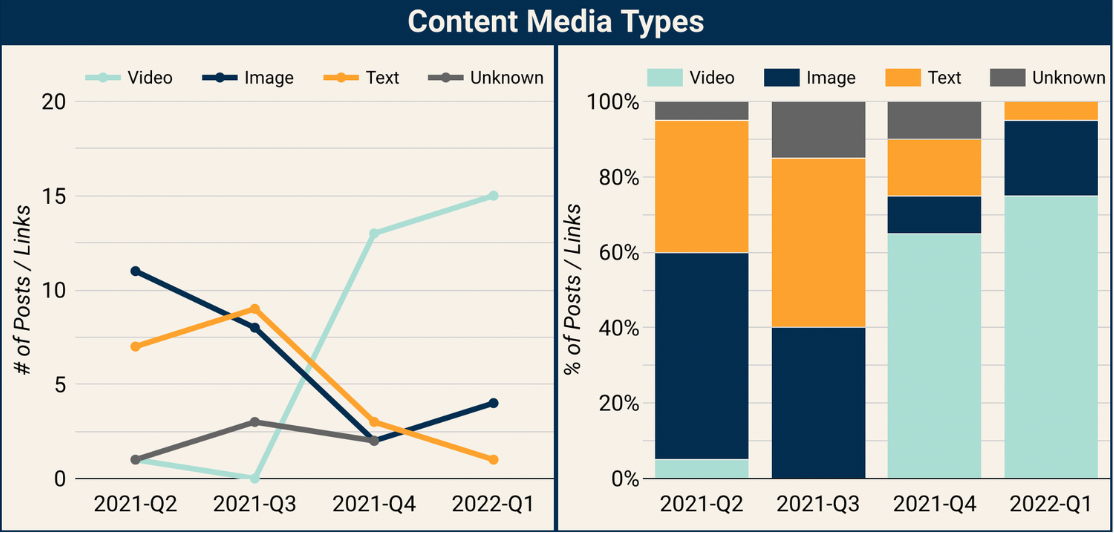
What has changed is the source of those videos. In Q4 of 2021, Instagram was the source of 11 of the 13 videos in the top 20 list. This time, Instagram is only 5 of the 15 videos. So Facebook Reels make up most of the videos on the list now. Interestingly, they are more likely to be from the original creators. And so part of the shift to more original content from Q4 2021 to the current list is because the very heavily unoriginal Instagram Reels have been replaced with more original Facebook Reels.
New Counting Method for Links
Facebook has changed what it considers to be a valid “link”. Previously, posts that included clickable links in their text counted. Now, only posts that render a “link preview” count as an impression on that link. Which has a dramatic impact on their list of the top links. Facebook released two lists this quarter, one without the “link preview” requirement, and one without. In the list without the requirement, none of the links received their views from posts where a link preview was rendered.

The effect this has on the results of our analysis is significant. Sharing links with stolen memes is a common, and highly effective, tactic that bad actors and more benign spammers like to use to get views and clicks to their domains. And so by excluding these posts from their view counts, Facebook is effectively hiding their activity from the public without doing anything to actually reduce the reach they achieve through the tactic.
The list with the “link preview” requirement includes many more well known news sources, such as TMZ, NBC News, and the BBC. As a result, this list has a lower rate of anonymous sources and sources sharing primarily unoriginal content. All the anonymous and unoriginal content is still there on Facebook, of course, we just will no longer be seeing it in the WVC Reports.
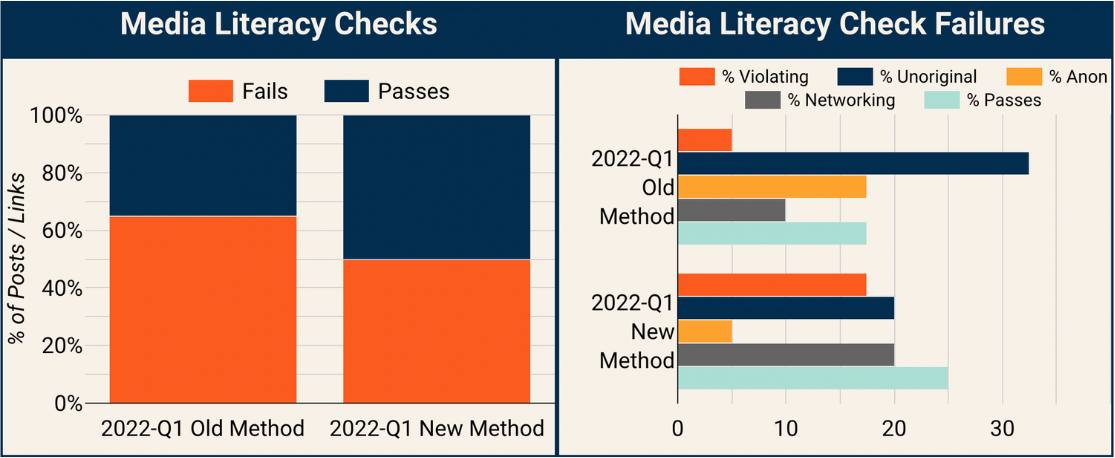
We have created a dashboard specifically to make clear all the differences between the two lists Facebook provided this quarter. For our analysis, we simply included both the lists but each with a weight of 0.5. Going forward, Facebook has said that they only release the “link preview” list, and so we expect the anonymous and unoriginal fractions to decrease in the Q2 WVC Report when it is released.
There is an interesting historical point to make here. In Facebook’s original attempt to release the WVC Report, in Q1 of 2021, it does appear that Facebook used a “link preview” requirement. Every link in the top 20 list of that original, unreleased report, which Facebook released after an investigation by the New York Times, got its distribution from posts where a link preview was shown. So, it would appear that the team behind the WVC Report originally wanted to include this requirement. However, according to the New York Times, Alex Shultz, now Chief Marketing Officer at Facebook, objected to the release of the report, due to possible COVID misinformation driving the top link in the list. Now, one year later, it looks like the team is reverting to their original intent behind the links list. And, funnily enough, as a result, we have our first example of labeled misinfo making it into the top content.
More Content is Violating Community Standards
The fraction of content on the list continues at the extremely high rate we saw in Q4 of 2021. And in fact, we have had to retroactively increase the rate we saw in Q4, because Facebook has labeled a domain that was in the Q4 list as violating in the Q1 list. This is thanks to the new practice Facebook will be using of giving us basic information about the violating content.
Alltrendytees.com
In addition to the first instance of misinfo in the WVC lists, we also see the first instance of a blatantly inauthentic network making it into the top lists. We have added an “Inauthentic” label in the Identity Transparency evaluation to cover when the creators are not simply being anonymous, but are blatantly lying to Facebook users about their identity.

Nayenews24.info
Nayenews24.info occupies 8 of the top links across the two lists in the Q1 2022 report. And Facebook has found it violating their policies against spam. They are now, thankfully, telling us this in the list themselves.
However, this domain was familiar to us, and in fact, we noted in the Q4 2021 report that this domain, which had the 15th most viewed that quarter, got there by spamming stolen articles across a network of groups. We assumed that Facebook found this to be fine, since the accounts appeared to be using their real names as they spammed the links, but apparently, Facebook has investigated and found evidence that they were violating policies. As a result, we have changed our assessment for the Q4 list and now label it as violating.

COVID Conspiracy Content
The fourth most viewed link on the “link preview” list is a YouTube video of testimony in a congressional hearing. The specific testimony was pushing a COVID related conspiracy theory, which has been debunked by Politifact and other fact checking organizations.
Every instance we could find of this link being shared on Facebook rendered with the fact check screen, which means the link was labeled false by a partner fact checker. As such, we have labeled the post as “Misinfo” in our accounting of violating content. This is the first example of fact check screened content making it into the lists in the WVC Report.
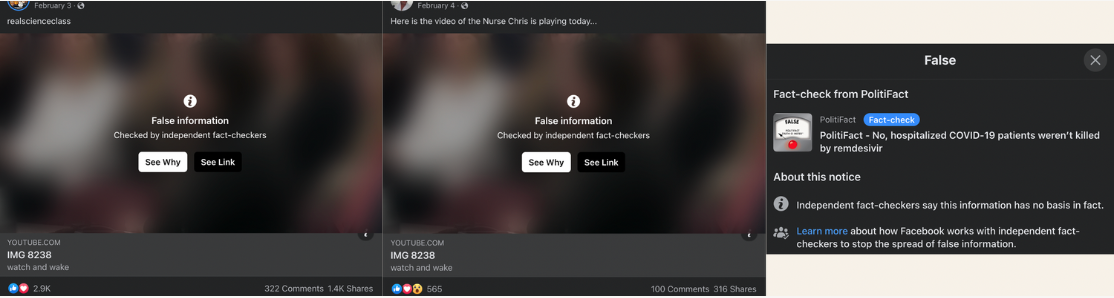
This example highlights a common pattern in how video based misinformation gets spread online. In general, YouTube has more permissive policies when it comes to hosting content. YouTube errs on the side of keeping content on the platform. However, their recommendation algorithms usually do a better job of not going off the rails and recommending misinformation. Facebook, relative to YouTube, has more restrictive policies on hosting video and will be more likely to remove videos. So, misinfo looks to YouTube for hosting, and to Facebook for distribution. A classic example of this is the “Plandemic” video. Facebook removed all copies of it. YouTube didn’t remove it, but did prevent it showing up in recommendations. And as a result, bad actors stitched the two platforms together, and were very successful in showing that video to millions of people. This case looks to be a repeat of that pattern.
Deep Dive on Alltrendytees.com: Flagrant Inauthentic Network
The 9th most widely viewed link for Q1 2022 is “alltrendytees.com”, and it reached that position by using a network of blatantly inauthentic groups and user accounts. Almost all of the links to that domain coming from Facebook are in a set of Groups that are all being used as a network. The groups are all targeting older American women, most of the content in the groups are memes about being a grandmother, or growing older, or about being a woman in general. They include the groups, “LAUGH WITH THE LADIES” (a group with 1.1M members), “Funnies That Makes You Laugh” (328k members), and “MIDDLE AGED HUMOR” (250k members). The admins across all the groups are identical, and are dominated by people who live in Bangladesh. There are also some duplicate accounts as admins of the groups.

Within the groups, almost every single post is a stolen meme paired with a link to alltrendytees.com.
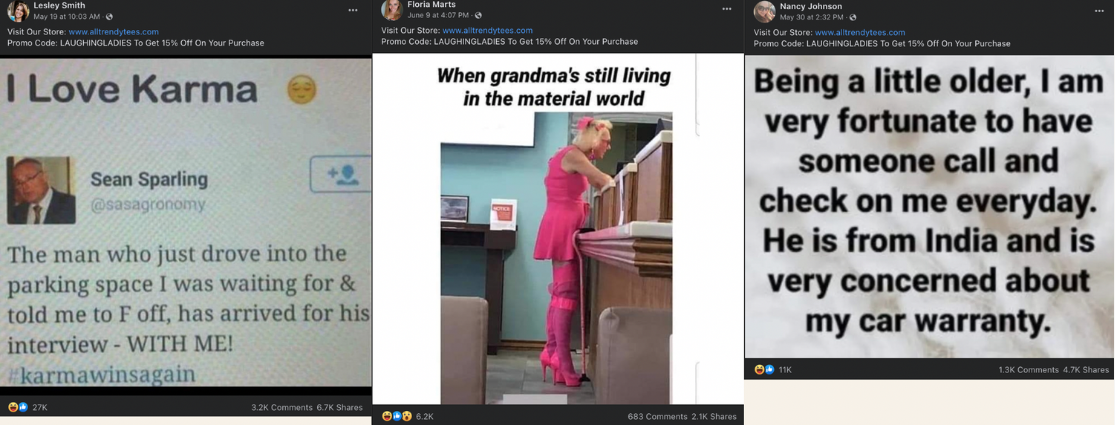
The users who are making the posts in the groups are not admins of the group, and they have American sounding names, like “Lesley Smith” and “Nancy Johnson”. However, when you click through to their profiles, it becomes clear that they are in fact men living in Bangladesh. The “Lesley Smith” profile says “I am a simple boy, so I am alone”, the profile image is stolen from a stock image website, and their home is listed in Bangladesh.
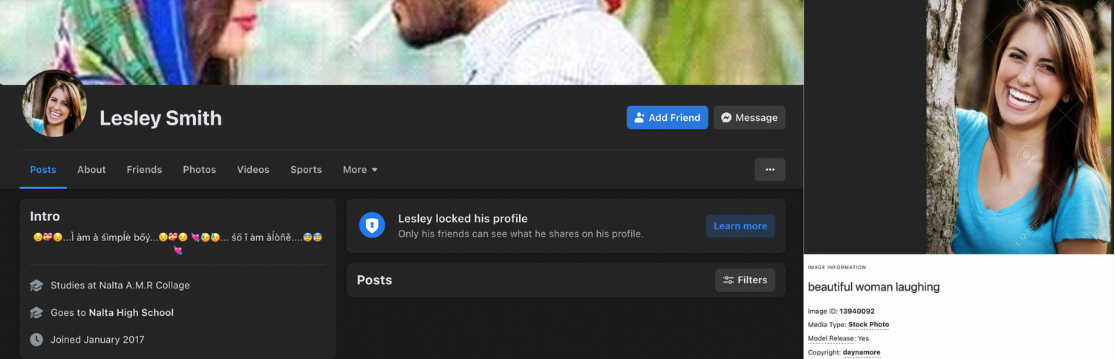
The profile for “Nancy Johnson” has the profile handle of “mdjulfikar.rahman.73”, also lists Bangladesh as home, and has a banner image that appears to be a young man of south Asian descent.

A similar story plays out for all of the accounts that are posting links to alltrendytees.com. They all have American sounding names and female profile pictures, but each of the user profiles has strong signs of actually being run by a man living in Bangladesh.
This is the first time we’ve seen clear coordinated inauthentic behavior (CIB) make it into the top lists in the Widely Viewed Content Reports. It should be genuinely alarming that such a clear and obvious CIB network could make it into the top content on Facebook and reach tens of millions of people. It is also alarming that Facebook will no longer be providing the list that caught this network going forward. We will no longer have the right list of content from Facebook to ensure that these networks don’t continue to reach tens of millions of Americans.
Appendix: Content Production Practices of the IRA
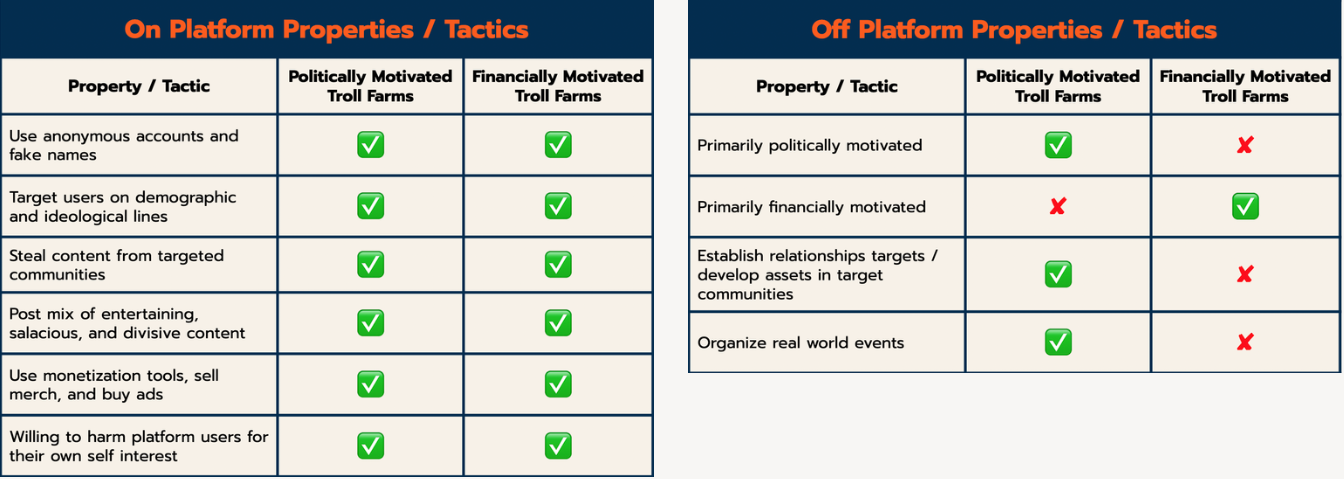
A criticism that is sometime brought up when the Internet Research Agency troll farms are compared to the Macedonian and other financially motivated troll farms is “The Macedonians weren’t troll farms. The IRA and the Macedonian operations were very different.” From a geopolitical perspective this is true. Financially motivated troll farms and politically motivated troll farms are politically different.
There have been many studies on the subject matter of the content the IRA shared, the audiences in America they targeted, the impact they had on American opinions, and their attempts to directly contact and mobilize American citizens (Examples from: Graphika, PNAS, New Knowledge). And there are important takeaways from studying the subject matter. A recent Cornell paper quantifying the broad topics they cover illustrates it well.
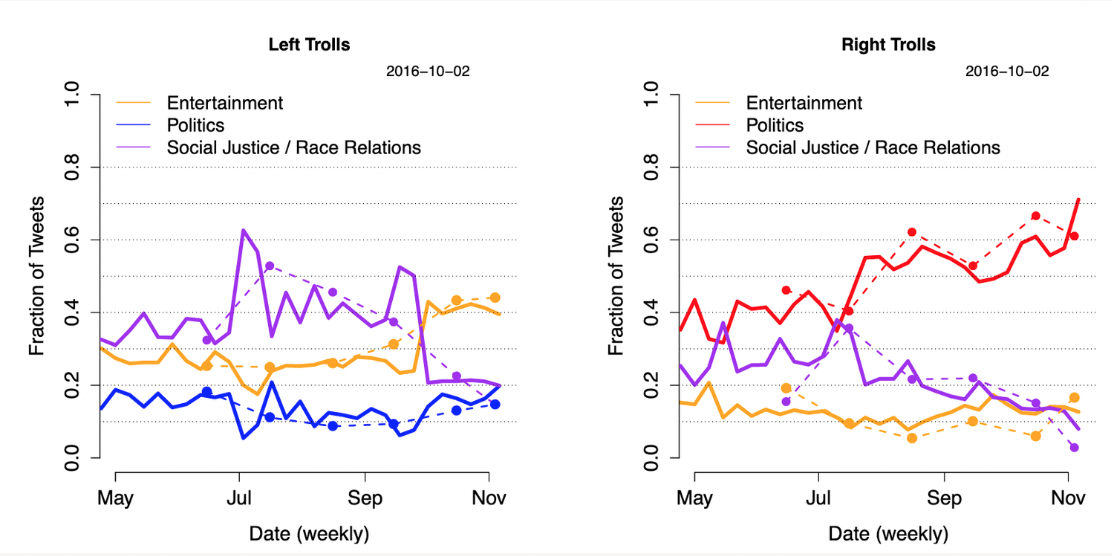
These charts show the subject breakdowns of 2016 IRA accounts that were right-leaning on subject matter or left-leaning. They illustrate that the IRA accounts spent a significant amount of their time on entertainment content. So just because an account is posting entertainment content, you still can’t be sure there aren’t more nefarious motivations behind it.
While a lot of attention has been given to what content the IRA posted and who they targeted with the content, less attention has been given to the how of it. How did they produce their posts? The above New Knowledge and Graphika reports touch on it, mentioning that they regularly get content from real Americans, the content production tactics the IRA used haven’t been broadly studied in a quantified way, at least not outside the companies.
When you study the IRA and Macedonian troll farms from a platform perspective, rather than a political one – when you study how they use the platforms, how they present themselves to users on the platform, and how they produce content they share on the platforms – they end up looking very similar. And in some cases, impossible to distinguish without private data like what devices and IP addresses they were using. In this section, we take a quick look at sample Tweets from the IRA to assess exactly how they produced content for their social media posts.
We will show that the dominant content production practice of the IRA was as follows
Decide on a “community of interest” you want to gain reach into
Create anonymous online accounts with branding / naming that would appeal to that community
Or use a fake name
Find other content creators already within that community that are producing either
Content that regularly goes viral within the community
Content that aligns with the message you want to spread in that community
Steal content from them and post it from your anonymous accounts
This is the exact same content strategy that North Macedonian and Kosovan groups used in 2016 and still use today.
Was this the only practice they used? No. But is it the dominant one they used? As we see in this study, yes. 100% of the content we evaluated in this quick study was stolen or repurposed. 52% of the content was posted from anonymous accounts. Which makes sense: that strategy is very good for audience building on platforms that don’t care about identity transparency, original content production, and don’t use responsible platform design and standard information retrieval signals in their algorithms.
Collecting IRA Content
Unfortunately, not every platform has a good repository of content that the IRA troll farms used to interfere with American communities. Facebook does not have an open collection of IRA content for us to study (Congress has released the ads that the IRA ran on Facebook, but this isn’t a fair representation of the IRAs activities on Facebook, and it was released in PDFs that make analysis difficult). The best collection of content from information operations is currently Twitter’s Information Operations Archive. There, they have every tweet and all media associated with the tweets from information operations they’ve removed since 2018. This includes the Tweets the IRA made in 2016 in the run up to the US Presidential Election. This is the content set we will use to study the IRA’s production practices.
We take all Tweets from Twitter’s “October 2018” release that
Are labeled as being in English or labeled as undefined language
Tweets with undefined language are usually image/video only and don’t have text content
Are from accounts that are labeled as being in English or as undefined language
Were posted between January 1st, 2016 and November 7th, 2016
Were not a basic retweet
This does a good job of selecting only Tweets that were part of the 2016 election operation. The total number of Tweets this collects is 378151, and this is the pool of Tweets from which we will pull some for evaluation.
Evaluating the Tweets
We obviously can’t evaluate 300,000 Tweets, so we will be sampling just a small subset. We sample Tweets randomly, weighted by how much total engagement they got (where total engagement is the sum of likes, replies, and retweets). This helps make sure we are looking at their tweets that had more impact.
This is intended to be a very quick study which answers a single question: what was the IRA’s dominant content production practice on Twitter in 2016? To answer this, we only need to sample and evaluate a small number of tweets. We selected 25 tweets in total. This feels like a small number, but it is sufficient to let us describe the IRA’s practices with a 10% precision. Meaning, we will be able to say “The IRA used tactic X around 40% to 60% of the time”, which is all we need here.
We run the tweets through the same evaluation process we used above in the analysis of the Widely Viewed Content Report. We want to know
How did the accounts present their identity?
Anonymous?
Examples: “1-800-WOKE-AF”, “TEN_GOP”, “Texas Lone Star”, “Black to Live”
Used a fake name?
Examples: “Crystal Johnson”, “Traynesha Cole 🌐”, “Pamela Moore”
Used their real authentic identity?
How did they produce the content they tweeted?
Stole it from communities of interest?
Repurposed existing content?
Created original content?
We answered these questions for the 25 tweets we sampled.
Results
For the 25 tweets we evaluated
22 of them were stolen content
3 of them were repurposed content
13 of them were from anonymous accounts
7 of them were from accounts that used fake names
For 5 of them, identity evaluation wasn’t possible since the data was hashed by Twitter

0 of the tweets contained actual, original content produced by the troll farm employees of the IRA. This actually allows us to put an upper limit on how much original content production the IRA actually used.

At most, 8.8% of engagement that the IRA got on Twitter in 2016 was from original content they made themselves, at the 90% confidence level (Meaning, there is only a 10% chance the true value is above 8.8%). At most, 8.8% of engagement that the IRA went to accounts that used real, authentic identities, either of people or organizations.
The dominant content production practices of the IRA are
Steal content and tweet it from anonymous accounts
Steal content and tweet it from accounts using fake names
Repurpose and tweak existing content and tweet it from anonymous accounts
Repurpose and tweak existing content and tweet it from accounts with fake names
And we can say this with over 90% confidence from evaluating only 25 tweets.
Summary
So, the dominant content production practices of the IRA troll farms match the North Macedonian and Kosovo operations: steal popular content from American communities and re-post. Even the subject matter is similar: they both posted a significant fraction of entertainment, funny videos, celebrity gossip, as well as charged political messages. The New Knowledge report even finds evidence that the IRA was selling t-shirts and merchandise for their accounts, so they are both making money from their operations. The real bottom line here is that when platforms create an incentive structure that rewards posting salacious and divisive content without any checks on how much effort creators are putting into content creation, politically motivated content farms and financially motivated content farms will all follow each other down the same path that leads to exploiting and trolling their target communities. And when most of the top content on a platform follows the same production practices as long established bad actors who have exploited communities for their own self interest, we should be concerned.
Data
You can find the Tweets we labeled, along with our full evidence of how we made our assessment, in this Google Sheet.
Examples
Example 1
This Tweet from the IRA represents a lot of what they did. Take a meme that went viral yesterday, re-post it with some hashtags and some light copy.

Example 2
This Tweet is a good example of one where they put slightly more effort into it. They found a hashtag that was already trending (#DNCleak), and then combined discourse that was already joined to the hashtag (freedom of speech) with quotes from the news of the day. Mashing them together to create something that wasn’t seen before tied to the hashtag. And it’s honestly pretty good work. This troll is ready for a promotion (Or maybe not, engagement was low). But still, they are just repurposing together existing ideas and content.

Example 3
These two Tweets highlight a common tactic they used to target the black community. Just steal their content from Tumblr. These are great examples of non-political content that the IRA posted. These are just funny videos and Tweet threads they are sharing. The purpose of them sharing it is so they can build up an audience within the black community and having a track record of Tweets like this helps make them appear authentic at first glance.


Example 4
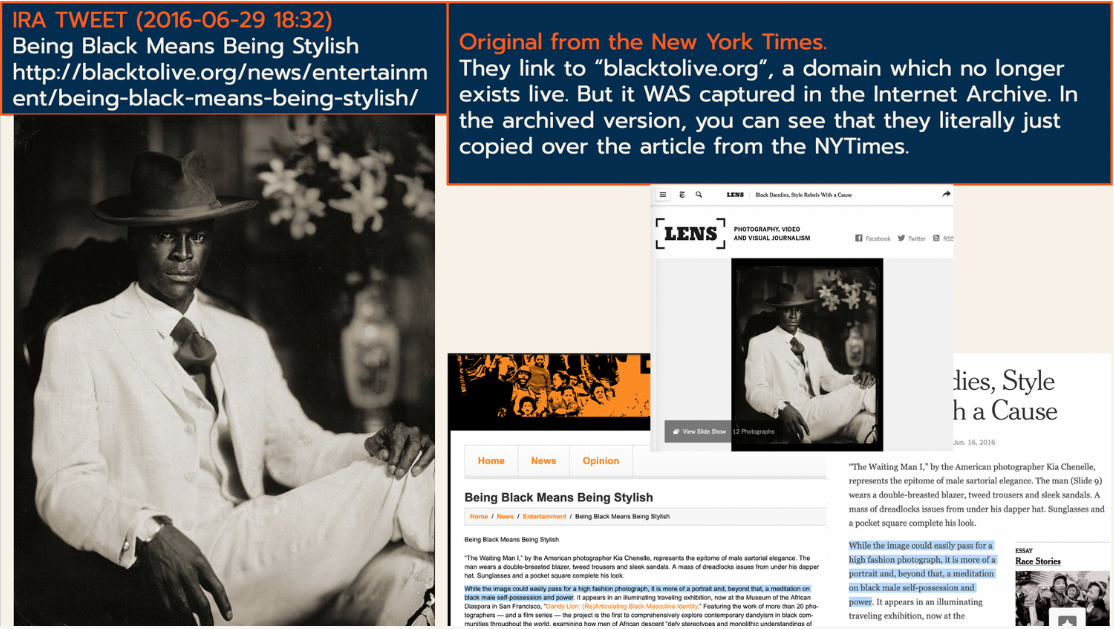
This example shows an example of how they used their domains. Here, they use a Tweet to link out to an article on their own domain, and use an image along with it. The domain obviously no longer exists, but when you look it up in the Internet Archive, you can see it was actually just copied, word for word, from a New York Times article. And the image they used was also from the NY Times. So, an example of the IRA troll farms using the exact same tactic that the Macedonian and Kosovan troll farms did! Copying and pasting news articles onto their own Wordpress setups.
Example 5
Another very standard example. Take a meme from 2010, mash it up with a relevant Tweet from the week before and send it.
